

Funcionamiento del sistema Mapa del Expediente
En ámbitos donde se maneja gran cantidad de información en texto, como el legal, las técnicas de inteligencia artificial, y especialmente de Procesamiento del Lenguaje Natural (PLN), han demostrado ser útiles y eficaces para organizarla y consultarla más rápidamente.
Para aplicar los últimos avances al sector legal, surge la colaboración del Instituto de Ingeniería del Conocimiento (IIC) y Garrigues, que han puesto a prueba un nuevo sistema: Mapa del Expediente, orientado a la organización y el tratamiento de expedientes judiciales de gran volumen.
Este sistema de inteligencia artificial integra el primer modelo de lenguaje adaptado al dominio legal, también desarrollado desde el IIC sobre la base de una nueva metodología para reajustar modelos existentes y que funcionen mejor con dominios del lenguaje y terminologías específicos.
Organización y análisis de expedientes judiciales
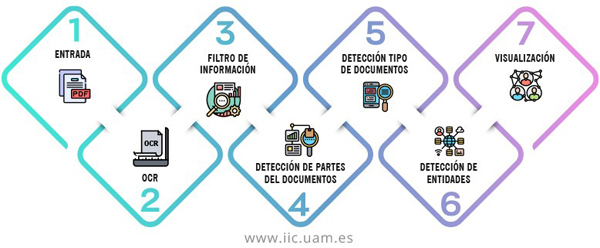
Mapa del Expediente es un sistema capaz de procesar todo tipo de documentación asociada a un expediente judicial, normalmente de gran volumen, para organizarla, catalogarla y analizarla de forma automática.
Una vez recibida la información en forma de ficheros PDF, mediante técnicas de OCR (Optical Character Recognition), se transcriben y digitalizan todas las páginas del expediente y se divide el volumen en partes o documentos individuales. Estos se catalogarán automáticamente dependiendo del escrito del que se trate: partes, actas de declaración, cédulas de citación, diligencias, providencias o autos, entre otros.
De esta forma, el sistema permite a los usuarios consultar rápidamente la información relevante, pero también identificar a personas o empresas que aparecen mencionadas en los diferentes documentos y establecer una red de relaciones entre estas entidades. Una información que puede además visualizarse en forma de grafo, conformando un auténtico mapa para navegar por el expediente.
Primer modelo de lenguaje del español legal
Mapa del Expediente cuenta a su vez con el primer modelo de lenguaje en español adaptado al sector legal. Este ha sido creado por el IIC según una metodología propia que permite adaptar modelos ya existentes a diferentes dominios del lenguaje, como el que se habla y se escribe en el sector legal.
Un modelo de lenguaje es una red neuronal artificial capaz de analizar ingentes volúmenes de texto escrito para aprender la estructura de un determinado idioma. Son ya conocidos modelos generales como BERT o GPT-3, que sirven de base y se ajustan para resolver distintas tareas de PLN: clasificación de documentos, resumen o traducción automática, generación de textos, entre otras.
No obstante, estos modelos pueden no funcionar tan eficazmente cuando se encuentran con los términos y la jerga empleados en sectores especializados, como el médico, el financiero o el legal. De ahí el interés por crear un modelo de lenguaje específico para cada ámbito con la metodología mencionada.
En este caso, se ha partido de BETO, el modelo general del español desarrollado por la Universidad de Chile, que se ha reentrenado con un gran corpus legal-administrativo de más de 500 millones de palabras. Los textos han sido recopilados de fuentes abiertas y curados por el equipo de lingüistas computacionales del IIC, garantizando su calidad.
Tras esta adaptación, se obtiene el primer modelo del lenguaje del español legal: Legal-BETO. Adicionalmente, y en una segunda fase de adaptación en colaboración con Garrigues, se utilizaron datos de expedientes recopilados por este despacho de abogados para generar una versión todavía más específica del modelo de lenguaje, bautizada como Garrigues-BETO y que se incorpora al sistema Mapa del Expediente.
Resultados de Mapa del Expediente
Ya puesto en práctica con Garrigues, Mapa del Expediente demuestra las ventajas de contar con un modelo de lenguaje adaptado al dominio legal. En concreto, se ha probado con dos problemas concretos del sector: la clasificación de documentos y la detección de entidades nombradas en el texto (personas, organizaciones y localizaciones). Entre los resultados experimentales, se ha podido comprobar que el modelo Garrigues-BETO ofrece mejores resultados que el estado del arte en modelos de lenguaje en español.
